| Citation: | YANG Lu, WANG Yiquan, LIU Jiaqi, DUAN Yulin, ZHANG Ronghui. An End-to-end Decision-making Method for Autonomous Driving Based on Twin Delayed Deep Deterministic Policy Gradient with Discrete[J]. Journal of Transport Information and Safety, 2022, 40(1): 144-152. doi: 10.3963/j.jssn.1674-4861.2022.01.017

|
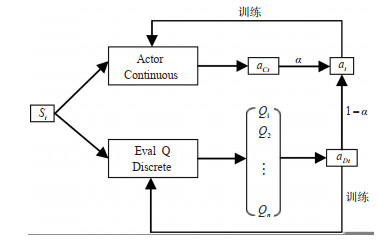
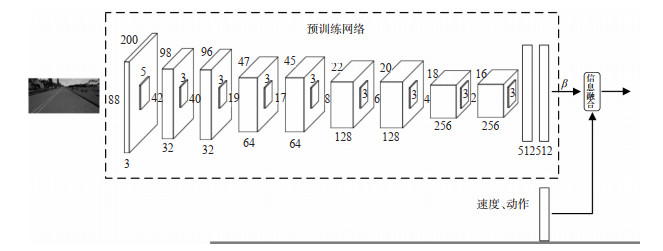
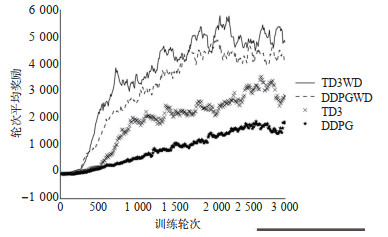
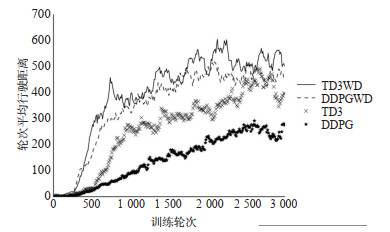
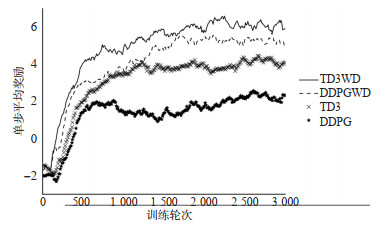
There are issues for the decision support method for automated driving based on reinforcement learning, such as low learning efficiency and non-continuous actions. Therefore, an end-to-end decision-making method for autonomous driving is developed based on the Twin Delayed Deep Deterministic Policy Gradient with Discrete (TD3WD)algorithm, which can be used to fuse the information from different action spaces over a network. In the network of traditional Twin Delayed Deep Deterministic Policy Gradient(TD3)algorithm, an additional Q network that outputs discrete actions is added to assist exploration training. Weighted fusion of the output actions of TD3 network and additional Q network is performed. The fused actions interact with the environment, in order to fully explore the environment and enhance the efficiency of the environment exploration. When the Critic network is updated, the output of the attached network is merged into the target actions as noise to encourage the agent to explore the environment and obtain better action estimates. Instead of the original images, image feature obtained from the pre-trained network is used as the state input to reduce the computational cost in the training process. The proposed model is tested under a set of simulated autonomous driving scenarios generated by Carla simulation platform. The results show that the convergence speed of the proposed method is about 30% higher than that of traditional reinforcement learning algorithms like TD3 and Deep Deterministic Policy Gradient(DDPG)under the training scenarios. Under the testing scenarios, the proposed method shows better convergent performances and the average rate of lane-crossing and the change rate of steering angle are reduced by 74.4% and 56.4% respectively.

| [1] |
熊璐, 康宇宸, 张培志, 等. 无人驾驶车辆行为决策系统研究[J]. 汽车技术, 2018, 515(8): 1-9. https://www.cnki.com.cn/Article/CJFDTOTAL-QCJS201808001.htm
XIONG L, KANG Y C, ZHANG P Z, et al. Research on behavior decision-making system for unmanned vehicle[J]. Automobile Technology, 2018, 515(8): 1-9. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-QCJS201808001.htm
|
| [2] |
黄玲, 郭亨聪, 张荣辉, 等. 人机混驾环境下基于LSTM的无人驾驶车辆换道行为模型[J]. 中国公路学报, 2020, 33 (7): 156-166. doi: 10.3969/j.issn.1001-7372.2020.07.016
HUANG L, GUO H E, ZHANG R H, et al. LSTM-based lane-changing behavior model for unmanned vehicle under environment of heterogeneous human-driven and autonomous vehicles[J]. China Journal of Highway and Transport, 2020, 33(7): 156-166. (in Chinese) doi: 10.3969/j.issn.1001-7372.2020.07.016
|
| [3] |
王鑫鹏, 陈志军, 吴超仲, 等. 考虑驾驶风格的智能车自主驾驶决策方法[J]. 交通信息与安全, 2020, 38(2): 37-46. doi: 10.3963/j.jssn.1674-4861.2020.02.005
WANG X P, CHEN Z J, WU C Z, et al. A method of automatic driving decision for smart car considering driving style[J]. Journal of Transport Information and Safety, 2020, 38(2): 37-46. (in Chinese) doi: 10.3963/j.jssn.1674-4861.2020.02.005
|
| [4] |
POMERLEAU D A. Alvinn: An autonomous land vehicle in a neural network[R]. Pittsburgh: Carnegie Mellon University, 1989.
|
| [5] |
巴明月. 基于条件模仿学习的端到端车道保持方法研究[D]. 重庆: 重庆理工大学, 2021.
BA M Y. Research on end-to-end lane keeping method based on conditional imitation learning[D]. Chongqing: Chongqing University of Technology, 2021. (in Chinese)
|
| [6] |
TOROMANOFF M, WIRBEL E, WILHELM F, et al. End to end vehicle lateral control using a single fisheye camera[C]. 2018 IEEE International Conference on Intelligent Robots and Systems(IROS), Madrid: IEEE, 2018.
|
| [7] |
CHEN J, YUAN B, TOMIZUKA M. Deep imitation learning for autonomous driving in generic urban scenarios with enhanced safety[C]. 2019 IEEE International Conference on Intelligent Robots and Systems(IROS), Macau: IEEE, 2019.
|
| [8] |
FUJIMOTO S, HOOF H, MEGER D. Addressing function approximation error in actor-critic methods[C]. International Conference on Machine Learning(ICML), Stockholm: PMLR, 2018.
|
| [9] |
PEROT E, JARITZ M, TOROMANOFF M, et al. End-to-end driving in a realistic racing game with deep reinforcement learning[C]. The IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Hawaii: IEEE, 2017.
|
| [10] |
MNIH V, BADIA A P, MIRZA M, et al. Asynchronous methods for deep reinforcement learning[C]. International conference on machine learning(ICML), New York City: JMLR, 2016.
|
| [11] |
KENDALL A, HAWKE J, JANZ D, et al. Learning to drive in a day[C]. 2019 International Conference on Robotics and Automation(ICRA), Montreal: IEEE, 2019.
|
| [12] |
QIU C R, HU Y, CHEN Y, et al. Deep deterministic policy gradient(DDPG)-based energy harvesting wireless communications[J]. IEEE Internet of Things Journal, 2019, 6(5): 8577-8588. doi: 10.1109/JIOT.2019.2921159
|
| [13] |
闫浩, 刘小珠, 石英. 基于REINFORCE算法和神经网络的无人驾驶车辆变道控制[J]. 交通信息与安全, 2021, 39 (1): 164-172. doi: 10.3963/j.jssn.1674-4861.2021.01.0019
YAN H, LIU X Z, SHI Y. Lane-change control for unmanned vehicle based on REINFORCE algorithm and neural network[J]. Journal of Transport Information and Safety, 2021, 39(1): 164-172. (in Chinese) doi: 10.3963/j.jssn.1674-4861.2021.01.0019
|
| [14] |
罗鹏, 黄珍, 秦易晋, 等. 基于DQN的车辆驾驶行为决策方法[J]. 交通信息与安全, 2020, 38(5): 67-77. doi: 10.3963/j.jssn.1674-4861.2020.05.008
LUO P, HUANGE Z, QIN Y J, et al. A method of vehicle driving behavior decision based on DQN algorithm[J]. Journal of Transport Information and Safety, 2020, 38(5): 67-77. (in Chinese) doi: 10.3963/j.jssn.1674-4861.2020.05.008
|
| [15] |
CHEN J Y, YUAN B D, TOMIZUKA M. Model-free deep reinforcement learning for urban autonomous driving[C]. 2019 IEEE intelligent transportation systems conference(ITSC), Auckland: IEEE, 2019.
|
| [16] |
ZHU M X, WANG Y H, PU Z Y, et al. Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving[J]. Transportation Research Part C: Emerging Technologies, 2020(117): 102662.
|
| [17] |
宋晓琳, 盛鑫, 曹昊天, 等. 基于模仿学习和强化学习的智能车辆换道行为决策[J]. 汽车工程, 2021, 43(1): 59-67. https://www.cnki.com.cn/Article/CJFDTOTAL-QCGC202101008.htm
SONG X L, SHENG X, CAO H T, et al. Lane-change behavior decision-making of intelligent vehicle based on imitation learning and reinforcement learning[J]. Automotive Engineering, 2021, 43(1): 59-67. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-QCGC202101008.htm
|
| [18] |
DOSOVITSKIY A, ROS G, CODEVILLA F, et al. CARLA: An open urban driving simulator[C]. Conference on Robot Learning(CORL), California: PMLR, 2017.
|
| [19] |
TOROMANOFF M, WIRBEL E, MOUTARDE F. End-to-end model-free reinforcement learning for urban driving using implicit affordances[C]. The IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Seattle: IEEE, 2020.
|
| [20] |
YI M L, XU X, ZENG Y J, et al. Deep imitation reinforcement learning with expert demonstration data[J]. The Journal of Engineering, 2018(16): 1567-1573.
|
| [21] |
CUI Y, ISELE D, NIEKUM S, et al. Uncertainty-aware data aggregation for deep imitation learning[C]. 2019 International Conference on Robotics and Automation(ICRA), Montreal: IEEE, 2019.
|
| [22] |
ZOU Q J, XIONG K, HOU Y L. An end-to-end learning of driving strategies based on DDPG and imitation learning[C]. 2020 Chinese Control and Decision Conference(CCDC), Hefei: IEEE, 2020.
|
| [23] |
MNIH V, KAVUKCUOGLU K, SILVER D, et al. Human-level control through deep reinforcement learning[J]. nature, 2015, 518(7540): 529-533. doi: 10.1038/nature14236
|
| [24] |
CODEVILLA F, MULLER M, LOPEZ A, et al. End-to-end driving via conditional imitation learning[C]. 2018 IEEE International Conference on Robotics and Automation(ICRA), Vancouver: IEEE, 2018.
|

Figures(8) / Tables(5)



 DownLoad:
DownLoad: